操作指南:列表采集--添加采集器--基本设置
1、指定采集器名称和采集器所属分类 采集器名称应该便于识别,分类用于方便管理。 2、指定目标页面编码 一般情况下只需要选择默认的自动,插件会根据采集页面自动确认编码。极

1、指定采集器名称和采集器所属分类
采集器名称应该便于识别,分类用于方便管理。

2、指定目标页面编码
一般情况下只需要选择默认的”自动“,插件会根据采集页面自动确认编码。极少数情况下需要你指定(例如DZ为简体中文GBK)。

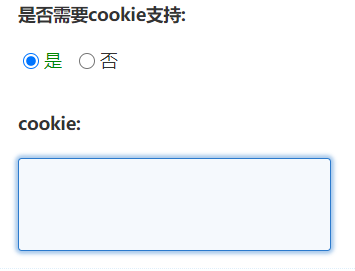
3、是否需要cookie支持
如果网站需要登录才能查看内容需要你指定cookie。
获取站点cookie的方法请参考"查看当前网站的cookie的两种方法"
特别提示:
使用本功能需要升级为VIP用户
1)、设定“是否需要cookie支持”为“是”并在文本框中输入cookie
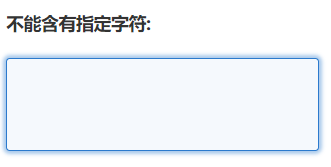
2)、填写“不能含有指定字符 “,当返回的页面中包含这些字符说明登录失败,需要重新指定cookie。
3)、填写“必须含有指定字符 “,当返回的页面中没有这些字符说明登录失败,需要重新指定cookie。

4)、在”测试地址“中指定一个链接用于测试。

5)、点击相看测试结果,即可在跳出窗口中获取采集结果。

如上图所示,点击“在游览器中查看页面”或“查看页面HTML源码”即可查看测试页面采集结果。
如果指定“不能含有指定字符 ”或“必须含有指定字符 “,将显示校验结果。

4、采集模式
采集模式包含:
- 规则模板
- 自定义
- 智能获取

根据选择的采集模式插件将自动显示不同的配置项目。
- 规则模板
- 自定义
- 智能获取
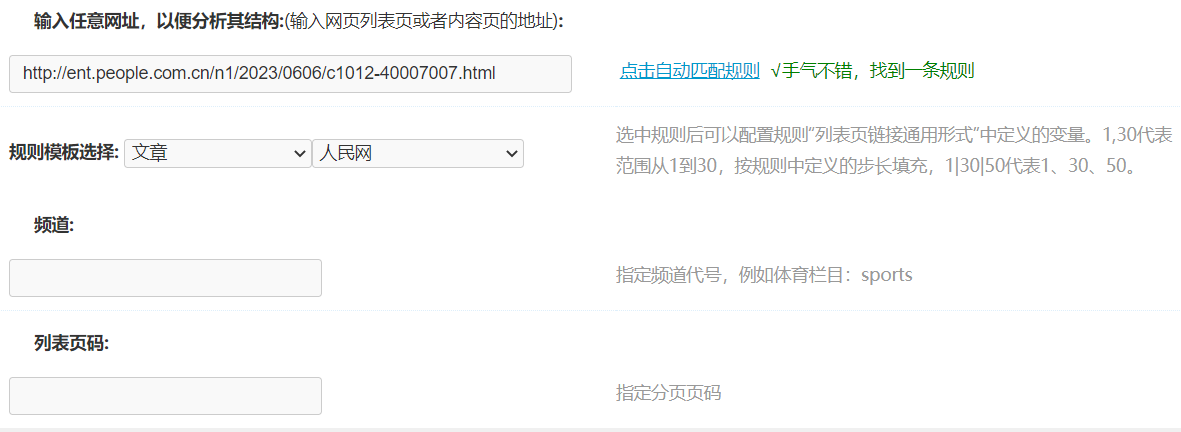
1、规则模板
输入目标站的任意列表或贴子网址,点击自动匹配规则,显示匹配的结果。

· 匹配的顺序是本地规则和云服务器规则。
特别提示:
匹配云规则需要升级为VIP用户
匹配到规则自动根据规则中"列表页地址通用形式"显示需要指定的变量。例如本例需要频道代号和分页页码。
3、自定义
2、一键采集
输入网页列表链接,一行一个。无需其他设置,提交就可以采集了。
插件尝试通过第一个链接匹配采集规则,如果匹配到了则使用该规则获取采集页面链接列表。如果不能匹配则采集给出的全部链接。
特别提示:
智能获取需要升级为VIP用户
